服务热线
4001616691

随着5G、大数据、物联网、AI 等新技术融入人类社会的方方面面,可以预见,在未来二三十年间人类将迈入基于数字世界的万物感知、万物互联、万物智能的智能社会。数据中心算力成为新的生产力,数据中心量纲也从原有的资源规模向算力规模转变,算力中心的概念被业界广泛接受。数据中心向算力中心演进,网络是数据中心大算力的重要组成部分,提升网络性能,可显著改进数据中心算力能效比。
从TCP到RDMA
传统的数据中心通常采用以太网技术组成多跳对称的网络架构,使用TCP/IP 网
络协议栈进行传输。但TCP/IP 网络通信逐渐不适应高性能计算业务诉求,其主要限制有以下两点:
限制一:TCP/IP 协议栈处理带来数十微秒的时延
TCP 协议栈在接收/发送报文时,内核需要做多次上下文切换,每次切换需要耗费5~10us 左右的时延,另外还需要至少三次的数据拷贝和依赖CPU 进行协议封装,这导致仅仅协议栈处理就带来数十微秒的固定时延,使得在AI 数据运算和SSD 分布式存储等微秒级系统中,协议栈时延成为最明显的瓶颈。
限制二:TCP 协议栈处理导致服务器CPU 负载居高不下
除了固定时延较长问题,TCP/IP 网络需要主机CPU 多次参与协议栈内存拷贝。网络规模越大,网络带宽越高,CPU 在收发数据时的调度负担越大,导致CPU持续高负载。按照业界测算数据:每传输1bit 数据需要耗费1Hz 的CPU,那么当网络带宽达到25G 以上(满载),对于绝大多数服务器来说,至少1半的CPU能力将不得不用来传输数据。为了降低网络时延和CPU占用率,服务器端产生了RDMA功能。RDMA是一种直接内存访问技术,他将数据直接从一台计算机的内存传输到另一台计算机,数据从一个系统快速移动到远程系统存储器中,无需双方操作系统的介入,不需要经过处理器耗时的处理,最终达到高带宽、低时延和低资源占用率的效果。
从IB 到RoCE
如下图所示,RDMA 的内核旁路机制允许应用与网卡之间的直接数据读写,规避了TCP/IP 的限制,将协议栈时延降低到接近1us;同时,RDMA 的内存零拷贝机制,允许接收端直接从发送端的内存读取数据,极大的减少了CPU 的负担,提升CPU 的效率。举例来说,40Gbps 的TCP/IP 流能耗尽主流服务器的所有CPU 资源;而在使用RDMA 的40Gbps 场景下,CPU 占用率从100%下降到5%,网络时延从ms 级降低到10μs 以下。
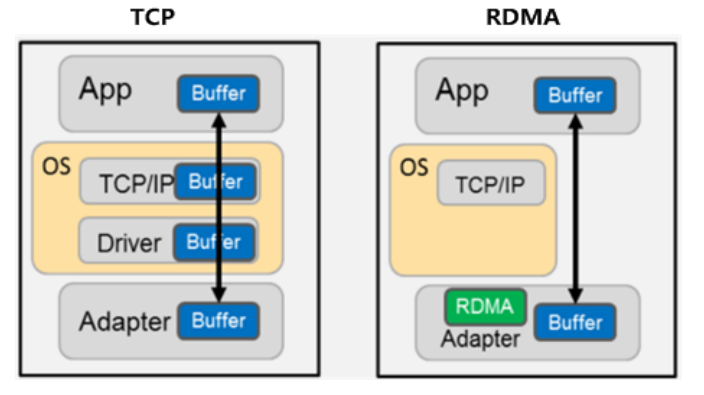
目前RDMA 的网络层协议有三种选择。分别是InfiniBand、iWarp(internet Wide Area RDMA Protocol)、RoC(RDMA over Converged Ethernet)。
InfiniBand 是一种专为RDMA 设计的网络协议,由IBTA(InfiniBand Trade Association)提出,从硬件级别保证了网络无损,具有极高的吞吐量和极低的延迟。但是InfiniBand 交换机是特定厂家提供的专用产品,采用私有协议,而绝大
多数现网都采用IP 以太网络,采用InfiniBand 无法满足互通性需求。同时封闭架构也存在厂商锁定的问题,对于未来需要大规模弹性扩展的业务系统,如果被一个厂商锁定则风险不可控。
iWarp,一个允许在TCP 上执行RDMA 的网络协议,需要支持iWarp 的特殊网
卡,支持在标准以太网交换机上使用RDMA。但是由于TCP 协议的限制,其性能上丢失了绝大部分RDMA 协议的优势。
RoCE,允许应用通过以太网实现远程内存访问的网络协议,也是由IBTA提出,是将RDMA技术运用到以太网上的协议。同样支持在标准以太网交换机上使用RDMA,只需要支持RoCE 的特殊网卡,网络硬件侧无要求。目前RoCE有两个协议版本,RoCEv1 和RoCEv2:RoCEv1 是一种链路层协议,允许在同一个广播域下的任意两台主机直接访问;RoCEv2 是一种网络层协议,可以实现路由功能,允许不同广播域下的主机通过三层访问,是基于UDP 协议封装的。但由于RDMA对丢包敏感的特点,而传统以太网又是尽力而为存在丢包问题,所以需
下一篇:没有了
24小时服务热线:4001616691
联系我们
Copyright © 2015-2044 北京中科新远科技有限公司 版权所有 京ICP备19012332号-1
地址:北京市-海淀区-上地信息路7号 昊海大厦305室